
How to run LLMs locally ⤵️ with Ollama

Why use local LLMs?
You can publicly access LLM (Large language models) for your day-to-day workflows via any of the providers by visiting their site.
In this blog series so far on Gen AI for testing, we’ve seen how ChatGPT.com could be used to generate test cases by understanding prompting, Github copilot for chat, and Copilot edits can be used with available models from Open AI and anthropic. If you are a new reader; welcome 👋 and feel free to subscribe and check out previous editions on automation hacks
These models are wonderful and powerful on the web, however, for any sophisticated use case, you will need access to their API. It’s quite cheap as of now but you’ll still need to get subscriptions ranging from $20 to $200 per month for OpenAI or Anthropic
With a business license, You mostly have guarantees that your data should be protected and secured but you may always have concerns at the back of your mind that your proprietary and confidential data is leveraged to train subsequent models, maybe even exposing your confidential company to data leaks. 🤷Plus a closed ecosystem blackbox is not a lot of fun, is it?
On the flip side, there is a thriving ecosystem of open-weight models that can be run on your local laptop or company infrastructure and leveraged for tasks suitable for LLMs. In this blog, we’ll take a look at Ollama which is one such solution built by the OSS community.
Ollama
I recently came across ollama, a wonderful tool that enables you to host local models and run inference. It has an MIT license code and 129K stars as of Feb 2025. Let’s understand how to set up ollama to host Deepseek and Llama, open-source models
Running LLMs locally and using CLI
We will run ollama using Docker to provide isolation and easy management of the Ollama Docker image
Let’s download the ollama image from the docker hub and start the container by running below
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Once this command finishes execution, we can verify that ollama is running by running below
docker ps -a | grep -i "ollama"
Next, let’s run a small model from meta LLama 3.2 with 1 billion params
docker exec -it ollama ollama run llama3.2:1b
Let’s also download deepseek-r1
docker exec -it ollama ollama run deepseek-r1
Other available models are
- Llama3.3 → 70B → 43 GB
- Llama3.2 → 3B → 2 GB
- Deepseek-r1 → 7B → 4.7 GB
Ollama also recommends certain heuristics for how much computing power you need to run these models locally
- 8 GB RAM to run 7B model
- 16 GB RAM to run 13B model
- 32 GB RAM to run 33B model
I have an Apple M1 Pro with 10 CPU and 32 GB RAM and this should be able to run llama3.2 and deepseek-r1 models comfortably, however since RAM may be required for other system processes, we’ll make sure our docker resource access is limited
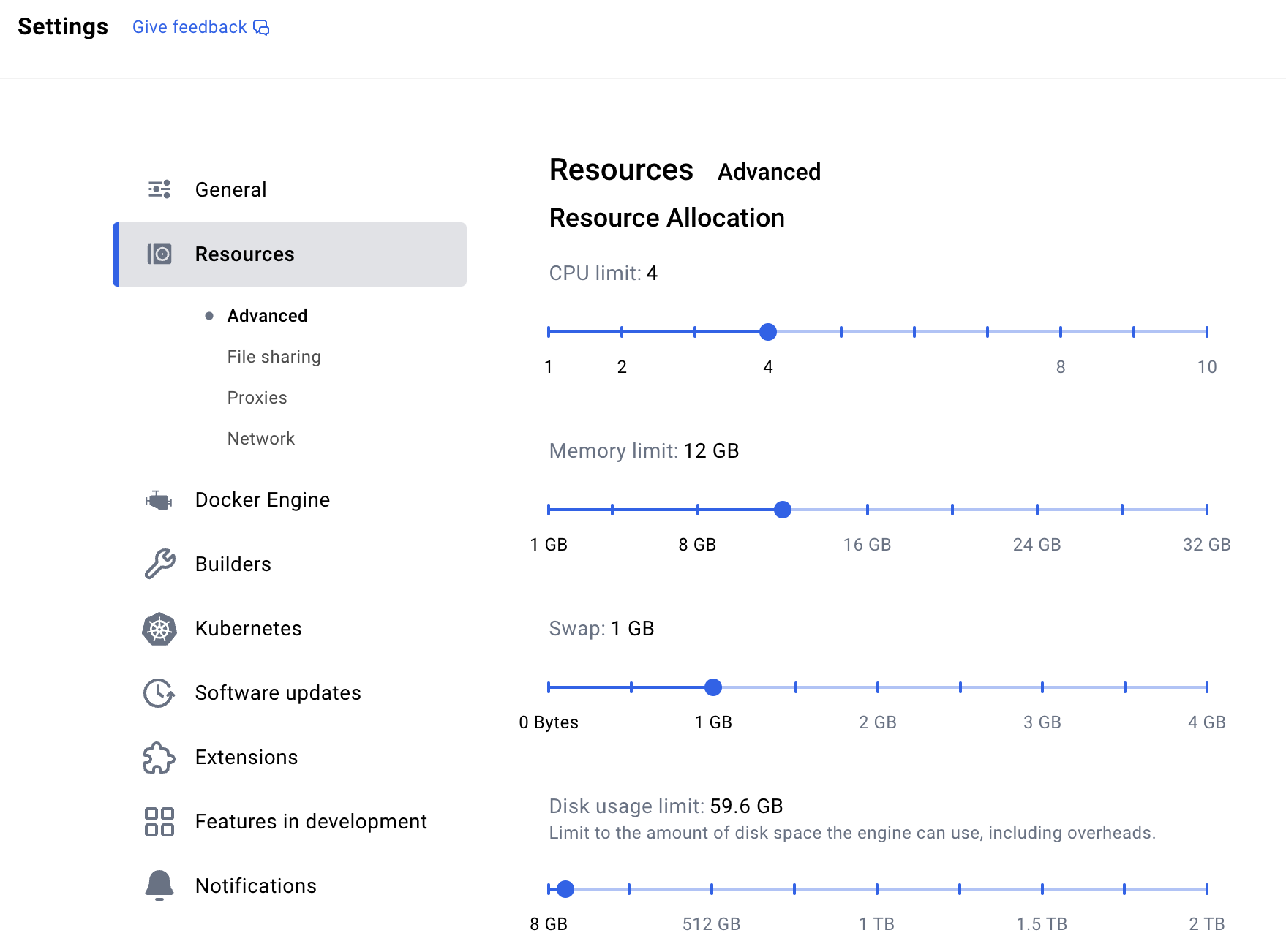
If you have docker desktop installed, you can go to Settings → Resources → Advanced and restrict the resources appropriately. For example
Once you run the above command, you should get a command line interface like below
You can type a prompt and get a response by using prompting techniques like we learned earlier.
Side note: Prompting an LLM is a super important skill to learn in 2025 and if you want to learn more you can refer to this cool course “All You Need to Know About Prompt Engineering” on educative to deep dive.
I’ll give the same prompt we gave earlier to generate some tests.
>>> """
... # MISSION
...
... 1. Generate test cases to test google homepage
... 2. Please Cover functional, non functional cases from web, mobile and backend perspective.
...
... # INPUT
...
... 1. Google home page is an app that takes the following inputs:
...
... * `Search box`
... * User can either click on `Google search button` or `I'm feeling lucky button`
...
... # RESPONSE FORMAT
...
... 1. csv with columns as `Test ID`, `Title`, `Preconditions`, `Steps`, `Expected Result`
... """
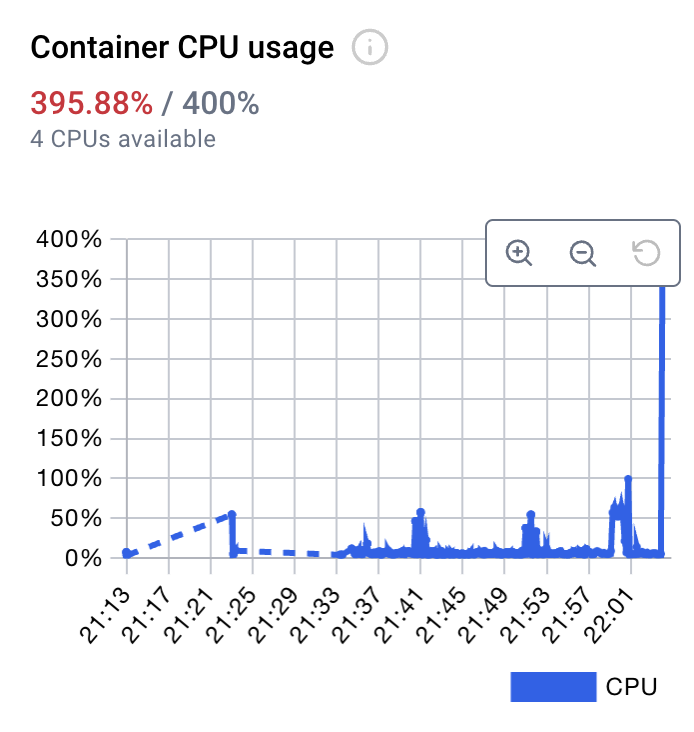
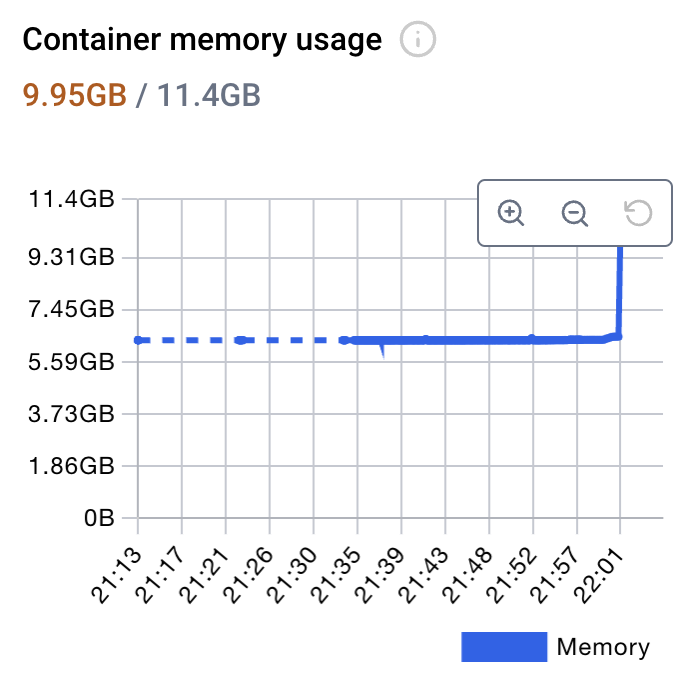
You can see CPU and memory spike up as the model tries to generate text as per your requirements.
It may be a bit slow but given more computing (CPU and memory) it should be able to return results faster
Below is what deepseek comes up with, along with the familiar chain of thought being exposed at the beginning
Okay, so I need to create test cases for Google’s homepage based on the user’s requirements. Let me break it down. First, the user mentioned covering both functional and non-functional tests from web, mobile, and backend perspectives. The inputs are the search box and two buttons: Google Search and “I’m Feeling Lucky.”
Starting with functional tests:
For the web interface:
- Test if the search box works when you type a query and press enter.
- Check if the search box updates the page correctly.
- Verify that clicking either button takes you to the corresponding search result.
Now, non-functional tests for the web might include performance metrics like load time, response time, and error handling on invalid inputs.
For mobile:
- Ensure the search box is functional but requires a long press or swipe for buttons.
- Check app store ratings and download stats.
Backend-wise, I need to test if Google can handle multiple requests simultaneously without crashing.
Non-functional tests here would involve load times with many users and stress testing under high traffic.
Wait, did I miss any cases? Maybe performance on different devices or network conditions for mobile. Also, error handling when there’s no internet connection—like not being able to sign in or search properly.
Reflection: In the current state even with 4 CPU and 12 GB RAM, the generation is quite slow and sequential. Boy, these LLMs while wonderful at text generation are super resource-hungry. I wonder if a day will come when the most powerful models will run on my phone at a fraction of the cost. 🧟God help you if you are trying to force fit LLMs to solve a problem that would otherwise be straightforward to solve via some other open-source library or tool, but hey, I don’t judge. You do whatever floats your boat.
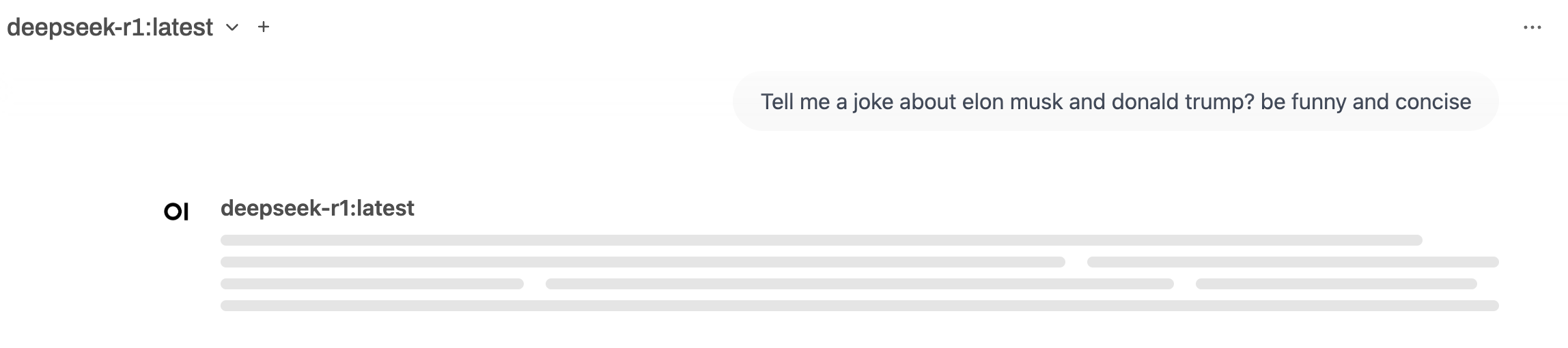
Also, deepseek-r1 by default uses reasoning and thus “thinks” longer while revealing its chain of thoughts (in this case 14 minutes for a joke). This example is trivial and not something to use the model for but still interesting to observe the reasoning patterns.
Does Ollama expose an API?
Now CLI and web GUI are cool and would help you with exploration in a more chat style, but what if you want to build some utility on top of LLMs, you gotta have an API
Ollama has a well-defined API surface that allows you to:
- Choose the model you want to use
- Send a text prompt and get the answer in the desired format
For example, say I wanted to write a playwright test using Java to open Google search and type a keyword
I could invoke the below API /generatemethod with the below options:
- Choose the model
- Write my text prompt.
- I also want to get all of the text in one shot so can set the stream as a false
- I’ve set the temperature as 0.8 for it to be creative.
curl --location 'http://localhost:11434/api/generate' \
--header 'Content-Type: application/json' \
--data '{
"model": "llama3.2:1b",
"prompt":"Write a playwright test in java to open google search and type in keyword meta llama. Make sure the code is clean, concise and follows best practices for modularity",
"stream": false,
"options": {
"temperature": 0.8
}
}'
And it came up with below
{
"model": "llama3.2:1b",
"created_at": "2025-02-25T01:14:15.302218386Z",
"response": "```java\nimport javax.swing.*;\nimport java.awt.*;\nimport java.awt.event.ActionEvent;\nimport java.awt.event.ActionListener;\n\npublic class SearchPanel {\n private JFrame frame;\n private JTextField inputField;\n private JButton searchButton;\n\n public SearchPanel() {\n createAndShowGUI();\n }\n\n private void createAndShowGUI() {\n // Create the main window\n frame = new JFrame(\"Google Search\");\n frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);\n frame.setLayout(new FlowLayout());\n\n // Input field for user input\n inputField = new JTextField(20);\n\n // Button to trigger search action\n searchButton = new JButton(\"Search\");\n\n // Add input field and button to the frame\n frame.add(inputField, new BorderLayout.CENTER);\n frame.add(searchButton, BorderLayout.SOUTH);\n\n // Connect search button's \"actionPerformed\" method\n searchButton.addActionListener(new ActionListener() {\n @Override\n public void actionPerformed(ActionEvent e) {\n String keyword = inputField.getText();\n if (keyword.length() > 0) {\n try {\n Process process = Runtime.getRuntime().exec(\"gnome-terminal -e --title=Google Search -t google.com -m \\\"Search for \" + keyword + \"\\\"\");\n process.waitFor();\n } catch (IOException | InterruptedException ex) {\n JOptionPane.showMessageDialog(frame, \"Error searching for '\" + keyword + \"': \" + ex.getMessage());\n }\n }\n }\n });\n }\n\n public static void main(String[] args) {\n SwingUtilities.invokeLater(new Runnable() {\n @Override\n public void run() {\n new SearchPanel();\n }\n });\n }\n}\n```",
"done": true,
"done_reason": "stop",
"context": [
128006,
9125,
...
74694
],
"total_duration": 21054774635,
"load_duration": 15001166,
"prompt_eval_count": 81,
"prompt_eval_duration": 61000000,
"eval_count": 339,
"eval_duration": 20978000000
}
I printed this in a Python shell to get more readable text
python3
>>> print(""" <insert response here> """)
And it returned below.
import javax.swing.*;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
public class SearchPanel {
private JFrame frame;
private JTextField inputField;
private JButton searchButton;
public SearchPanel() {
createAndShowGUI();
}
private void createAndShowGUI() {
// Create the main window
frame = new JFrame("Google Search");
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
frame.setLayout(new FlowLayout());
// Input field for user input
inputField = new JTextField(20);
// Button to trigger search action
searchButton = new JButton("Search");
// Add input field and button to the frame
frame.add(inputField, new BorderLayout.CENTER);
frame.add(searchButton, BorderLayout.SOUTH);
// Connect search button's "actionPerformed" method
searchButton.addActionListener(new ActionListener() {
@Override
public void actionPerformed(ActionEvent e) {
String keyword = inputField.getText();
if (keyword.length() > 0) {
try {
Process process = Runtime.getRuntime().exec("gnome-terminal -e --title=Google Search -t google.com -m \"Search for " + keyword + "\"");
process.waitFor();
} catch (IOException | InterruptedException ex) {
JOptionPane.showMessageDialog(frame, "Error searching for '" + keyword + "': " + ex.getMessage());
}
}
}
});
}
public static void main(String[] args) {
SwingUtilities.invokeLater(new Runnable() {
@Override
public void run() {
new SearchPanel();
}
});
}
}
I don’t know Playwright API well enough yet but this probably looks wrong, for some reason Llama thought it needed to create a Java AWT component for search
In reality, it should look something like below
package org.example;
import com.microsoft.playwright.*;
public class App {
public static void main(String[] args) {
try (Playwright playwright = Playwright.create()) {
Browser browser = playwright.chromium().launch();
Page page = browser.newPage();
page.navigate("<http://playwright.dev>");
System.out.println(page.title());
}
}
}
Friendly reminder: models could be wrong and we as engineers need to use judgment to choose the right one for the use case and prompt them well, I think providing some examples of what you are looking for may help yield better results but that’s an exercise I’ll leave to you.
And that’s all folks! 🥕
Conclusion
Let’s do a quick recap, shall we?
Hopefully, you take away the below
- Ollama can run on docker containers and run open weights models on your infrastructure like Llama, deepseek, etc
- You can use CLI, Open Web UI for chat, or an extensible API to build on top of
- Choosing the right model/size for the use case is important
- Deepseek-r1 reasoning models are slower but can spew more accurate results
- Models can be wrong or hallucinate; don’t forget to check their work and learn the topic yourself before using their output.
The world still needs you 🫵, you human engineer. Don’t gaslight yourself with Gen AI hype and give up just yet! I’m rooting for you!
Enjoyed reading this?
Subscribe to the newsletter and YouTube channel (@automationhacks) for more ⚡insights into software testing and automation, or connect on topmate for a personalized 1:1 session.
Disclosure: I’ll earn a small commission if you decide to purchase some of the educative.io text courses linked in the blog for your learning and growth. Their system design courses and grokking coding interview courses are arguably quite helpful for interview prep.
Until next time, happy testing!
Comments