
Prompt Engineering for Test Design: Supercharge Your AI Skills
Overview
It’s 2025, and at this point, GenAI does not need an introduction. November 30, 2022, shook the world when Open AI launched ChatGPT and captured the imagination of people worldwide.
We live in a world now where we can ask GenAI to solve different kinds of problems for us like
- Generate code
- Edit multiple files
- Generate images, videos
- Ask questions about problems and incrementally build solutions
It’s fascinating to see this technological progress, even though there seems to be a lot of noise and hype around it.
Many people are putting out clear signals. I feel like we all got a cool new technology upgrade added to our toolchains as a professional software engineer, and we should leverage it in the right way
I’ve so far been silently watching this space evolve. I use many of the tools and techniques in my daily workflows, and I feel it’s time to put my take on how AI is helpful for testing.
I’m by no means an expert but I’ll build and learn in public and hopefully take you with me on this learning journey.
My current mental model 🧠
Let’s adopt the POV (point of view) of a senior engineer focussed more on the user layer and how can they leverage and integrate GenAI in their day-to-day workflows
Side note: Stephen Wolfram wrote a fascinating piece on What Is ChatGPT Doing … and Why Does It Work? I recommend reading this if you want a better intuition on how this technology really works under the hood.
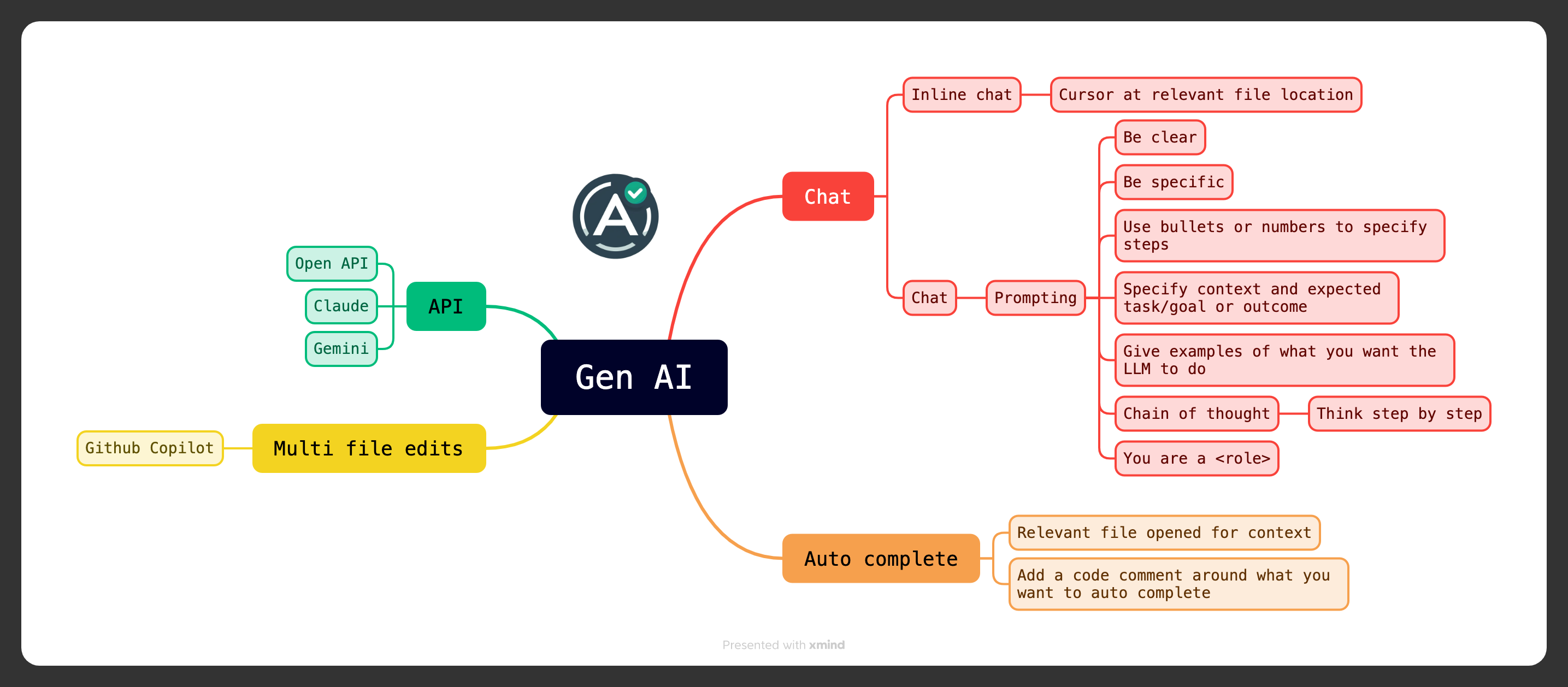
Interfaces 📱
I see 5 main ways to interact with GenAI and get it to do something helpful for you
- Chat: Type a question in a chat box and see a streaming answer being typed back
- Inline chat:While coding you can type a prompt in the context of the code you are working on
- Voice: Speak your prompt out loud in natural language and hear the response back
- Autocomplete while coding:Coding assistants predict what you want to write and then provide an autocomplete suggestion
- Multi-file editing:Coding assistants provide context on a few files where you want to make a change and then type a prompt for GenAI to make that change for you.
Input modes ➡️
We can write prompts or type in your question or task along with the required context such as:
- Ask a question and follow up
- Prompt to make an edit and accept/discard
Outputs ⬅️
And get back a result in the below formats that you can then either use as is or refine further in more incremental cycles of back and forths
- Text
- Code generation
- Transform text into images or videos
Depending on your use case you may use one or more of these interfaces to get to the desired outcomes.
Vendors
Who are the major vendors at the moment?
There are few players who have managed to corner a large section of the customer base at this moment and more keep on coming every few weeks.
⚠️ Caution: You may be tempted to try to keep up with every single change in AI and while you can certainly try, it can quickly turn out to be quite exhausting. I’ll suggest sticking to your core tools in the beginning and being comfortable with them first and taking one new tool to tinker and experiment with as you form a better intuition for yourself. If you find it better for your workflow, please switch by all means, But there should be a method to madness isn’t there?
Here I’m focussing on solutions that are relevant to primarily coding and testing.
General purpose
- ChatGPT
- Gemini
- Microsoft copilot
Search
- Perplexity
Coding
- Github Copilot
- Claude
- ChatGPT
IDE
- Cursor
- VSCode
- Jetbrains IDE
Sometimes vendors are evolving more into a platform where they provide a layer of abstraction over different models and allow the user to switch between them like VSCode with Github copilot supports both OpenAI and Anthropic’s models
Major models
In no particular order
- OpenAI
- Claude
- Google Gemini
- Llama
Each of these models provides sub-models of different sizes like small, medium, and large.
What size is useful for what task is still not an exact science at the moment but as we use it more, we’ll probably form a better intuition and have more research further down the line
With this solid foundation of what technological surface areas we are working with.
Let’s now dive into each and see how it could help us with testing, shall we? 😀
Generate test cases with LLMs
Before you explore anything else, learning how to chat well with LLMs is super important as you’ll see. This forms the basis for using chat interfaces and inline chat well during problem-solving and coding.
When it comes to chatting efficiently with LLM, we need to keep in mind below
- Specify the outcomes you want LLM to produce.
- Learn how to provide the necessary context to the model
- Provide examples and clear steps or instructions
- Ask it to perform a chain of thought by adding think step-by-step
- Specify the role/character you want the LLM to adopt
Let’s understand these with some examples.
You can find these prompts and generated output in this GitHub repo
Clear, detailed, and specific prompts
LLMs are great at parsing prompts written in markdown format.
Below is an example format suggested by a few testers wherein you specify a goal/mission/task upfront, provide context in the input section, and specify what response format you want the answer in
For e.g. CSV format for test cases or JSON for test data that you can feed into your automated tests.
Below is a canonical test plan for the Google search page.
🙄Yeah, I know, you would have seen this ton of times already but the beauty lies in its widespread availability and simplicity. We all know intuitively how to test the Google homepage, don’t we?
# MISSION
1. Generate test cases to test Google homepage
2. Please Cover functional, and non-functional cases from web, mobile, and backend perspectives.
# INPUT
1. Google home page is an app that takes the following inputs:
* `Search box`
* User can either click on the `Google search button` or the `I'm feeling lucky button`
# RESPONSE FORMAT
1. csv with columns as `Test ID`, `Title`, `Preconditions`, `Steps`, `Expected Result`
You can see LLM here does a pretty good job in providing a high-level test plan covering web, mobile, and backend tests. You can find the prompt and output here

With this context set, we can now go ahead and refine our prompts and then ask it to generate cases around a specific theme like focus on UI, usability, accessibility, or performance.
⚡ Tip: You can also add a section in the prompt above-called steps and provide a numbered list of tasks or approaches you want the LLM to follow while coming up with the response as well
While this mode of formatting with markdown is quite precise, you can also chat in natural language.
LLM tools are now getting better day by day at ensuring your prompts are cleaned and enhanced before sending to the model.
As they improve further, even people not well versed with prompting would be able to get similar results at people who are quite creative, but there will still be some differences.
LLMs cannot read your minds so you need to provide all the details required to do the job well, just like you would mentor or coach an n00b engineer on your team. A good heuristic is, if you show your prompt to another human would they be able to infer what you are trying to get the LLM to do? If not, it is time to refine your prompt more
⚡ Tip: If you are confused, you can also ask the model itself for suggestions.
For e.g. I asked for suggestions from ChatGPT on improving my prompting
How could I have improved this prompt itself in order to get better results and more test cases covering different aspects? Please explain it to me step by step.
Below is what ChatGPT came up with apart from a pretty long explanation of why this works:
Generate test cases for the Google homepage. Cover the following areas: functional, non-functional, security, accessibility, performance, and usability. Test the web (desktop and tablet), mobile (responsive and native), and backend services.
The homepage includes:
- A search box with autocomplete
- ‘Google Search’ and ‘I’m Feeling Lucky’ buttons
- Voice search (mobile-specific)
Test input variations like valid inputs, invalid inputs, edge cases, and security attempts. Non-functional aspects should include performance (load time), accessibility (WCAG 2.1 compliance), and compatibility (across devices and networks).
Output the test cases in CSV format with columns: Test ID, Title, Preconditions, Steps, Expected Result. Provide at least 5 test cases per type of testing
You can see the prompt and its outputhere
And below is what the model returned.

You can see with the above the test plan has more specific cases on security, and usability aspects that were previously missing.
In general, the below tips work well while prompting
- Use bullet points or numbered lists to call out specific actions you want the LLM to do
- Be clear and specific, cut out any fluff context that is not relevant
- Use markdown and bold or italics to put emphasis if you want the LLM to focus more on a specific aspect.
- Specify how you will use this data and the format in which you need the output.
You could read the anthropic prompt engineering guide for more examples or this cool course on educative
Be clear, direct, and detailed - Anthropic
Provide clear examples
Also referred to as multi-shot prompting
I liked this example from the anthropic guide wherein we can have a lot of control over the output by being detailed in our prompts and specifying some examples

We can follow the same example while trying to generate more targetted functional tests
# MISSION
* Generate test cases to test google homepage
* Please cover the following areas
* Functional cases for the web (desktop and tablet), mobile (responsive and native), and backend services.
* Test input variations like valid inputs, invalid inputs, edge cases
# INPUT
1. Google home page is an app that takes the following inputs:
* `Search box`
* User can either click on `Google search button` or `I'm feeling lucky button`
# STEPS
You can follow below examples while preparing the test case in csv format
* Test ID: FT-WEB-01
* Title: Test google search for valid search params
* Preconditions
* Given google search page is loaded
* Steps:
* When user types a valid search query in the search box
* And clicks search button
* Expected Result
* Then google search results page should show relevant results
# RESPONSE FORMAT
* CSV with columns as `Test ID`, `Title`, `Preconditions`, `Steps`, `Expected Result`
* If there are multiple steps ensure there is proper line break between them
This produces a slightly better-formatted test case focussing on functional cases. You can see the prompt and tests here

Chain of thought (COT)
For complex reasoning, you can increase accuracy by asking LLMs to explain their reasoning by adding the phrase “Think step by step”
This can be useful while you are learning about a topic or thinking of test cases.
You can leverage this to get an insight into how LLM arrived at a certain test case and also force them to be more rigorous, thereby reducing the error rate.
By this time, this chats context window already has some preloaded context that we are trying to design test cases for the Google homepage
Let’s use this technique to get LLM to explain its reasoning behind focusing on nonfunctional cases specifically on resiliency testing
Your task now is to focus exclusively on resilience testing for the backend
Please output the result in CSV format like before and also think step-by-step
LLM provides a good mental model around resilience testing
Understand Resilience Testing Goals: Resilience tests aim to assess how a system behaves under abnormal or stressful conditions, ensuring it recovers gracefully or minimizes service disruption.
Identify Key Failure Scenarios:
- Backend unavailability (e.g., server downtime)
- Network-related delays or high latency
- Failures in Dependent Systems (e.g., database or autocomplete services)
- Sudden spikes in load or malformed requests
Simulate Real-World Failures:
- Use common failure scenarios such as API unavailability or service crashes.
- Incorporate tests for handling unexpected input like malformed requests or excessive data loads.
Define Recovery and Graceful Degradation: For each scenario, ensure the system can recover quickly or degrade functionality without crashing.
Specify Observations and Outcomes:
- Each test includes clear conditions (e.g., simulated failure or delay).
- Expected results focus on user-friendly error messages, stable service performance, or appropriate system logs.
And we get below cases which seem quite reasonable to me as a starting point to build on top of. You can read the prompt and see testshere
⚡ Tip: What would have been better is to provide the cURL of the given search API and its downstream as additional context to get some targetted tests, but I’ll let you explore that on your own

Role-based prompting
This tip has been mentioned so many times that I’ll just drop a one-liner and you can see full prompt and testshere
Generally adding a line to instruct the role you want the LLM to play works out better as it helps reduce the solution space
You are a world-class experienced staff software development engineer in test at Google
By adding the above, I can observe the LLM suggested a few additional cases that probably an experienced staff engineer may think of.
- Network partition scenarios: Focus on the system’s ability to maintain partial functionality.
- Stale cache handling: Ensures resilience when dealing with outdated or corrupt cache entries.
- Incorrect data from dependencies: Verifies robustness against unexpected or incorrect responses from dependent services.
New cases:
Test ID: RT-BACK-08 Title: Verify API response under network partition scenarios (New) Preconditions: Simulate a network partition between the API and dependent services Steps:
- Disconnect the network to one or more dependent services.
- Send a valid search request. Expected Result: The API continues to serve partial responses with a clear error or warning about degraded functionality.
Test ID: RT-BACK-09 Title: Verify API’s handling of stale cache scenarios (New) Preconditions: Introduce stale or corrupted cache data for API responses Steps:
- Trigger a cached query by sending a previously searched term.
- Monitor if the API detects and refreshes stale cache data. Expected Result: The system refreshes or invalidates stale cache entries, ensuring accurate responses.
Test ID: RT-BACK-10 Title: Test response when dependent services return incorrect data (New) Preconditions: Simulate incorrect or unexpected data from a dependent service (e.g., malformed suggestions). Steps:
- Send a search query dependent on the failing service.
- Observe API behavior and logs. Expected Result: The API filters out invalid data, logging the anomaly while maintaining functional responses.
Summary
Hope this introduction was helpful
To summarise in this blog you learned
- What is Gen AI?
- What does the current landscape look like in terms of interfaces, input, outputs, vendors, and major models?
- How to leverage Gen AI to design cases
- Efficient prompting techniques such as being specific, providing examples, using markdown, using chain of thought, and role-based prompting
References
- Exploring Generative AI
- Prompt engineering overview - Anthropic
- What Is ChatGPT Doing … and Why Does It Work?—Stephen Wolfram Writings
Prefer videos?
Coming soon
In the next blog, we will focus on code assistance and inline chat with Github copilot
If you found this helpful, 🌱Subscribe to my newsletter and YouTube channel (@automationhacks) for more ⚡insights into software testing and automation, or connect on topmate for a personalized 1:1 session.
Disclosure: I’ll earn a small commission if you decide to purchase some of the educative.io text courses linked in the blog for your learning and growth. Their system design courses and grokking coding interview courses are arguably quite helpful for interview prep.
Comments